比较排序算法
比较排序如其名,需要通过比较两个元素的大小来确定他们的前后序列。
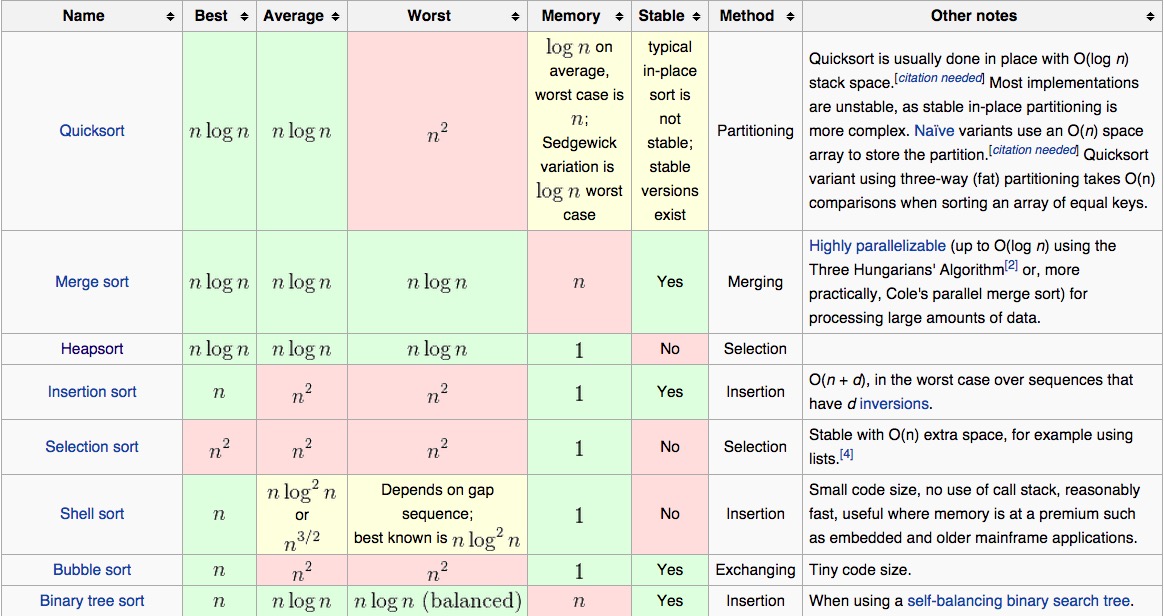
- 性能限制和优势
比较排序有很多性能上的根本限制。在最差情况下,任何一种比较排序至少需要O(nlogn)比较操作.这是比较操作所获的信息有限所导致的,或者说是全序集的模糊代数结构所导致的。从这个意义上讲,归并排序,堆排序在他们必须比较的次数上是渐进最优的。 因此比较排序的最好情况为nlogn的复杂度。
不过,比较排序在控制比较函数方面有显著优势,因此比较排序能对各种数据类型进行排序,并且可以很好地控制一个序列如何被排序。例如,如果倒置比较函数的输出结果可以让排序结果倒置。或者可以构建一个按字典顺序排序的比较函数,这样排序的结果就是按字典顺序的。
比较排序可以更好地适应复杂顺序,例如浮点数。并且,一旦比较函数完成,任何比较算法都可以不经修改地使用;而非比较排序对数据类型的要求更严格。 这种灵活性和上述比较排序在现代计算机的执行效率一起导致了比较排序被更多地应用在了大多数实际工作中。
原始输入数据情况:
- 平均情况:Random
A random initial order is often used to evaluate sorting algorithms in order to elucidate the “typical” case
- 最好情况 Sorting nearly sorted
It is quite common in practice. Some observations:
Insertion sort is the clear winner on this initial condition. Bubble sort is fast, but insertion sort has lower overhead. Shell sort is fast because it is based on insertion sort. Merge sort, heap sort, and quick sort do not adapt to nearly sorted data.
- 最坏情况 Reversed Initial Order
Sorting an array that is initially in reverse sorted order is an interesting case because it is common in practice and it brings out worse-case behavior for insertion sort, bubble sort, and shell sort.