比较排序算法
比较排序如其名,需要通过比较两个元素的大小来确定他们的前后序列。
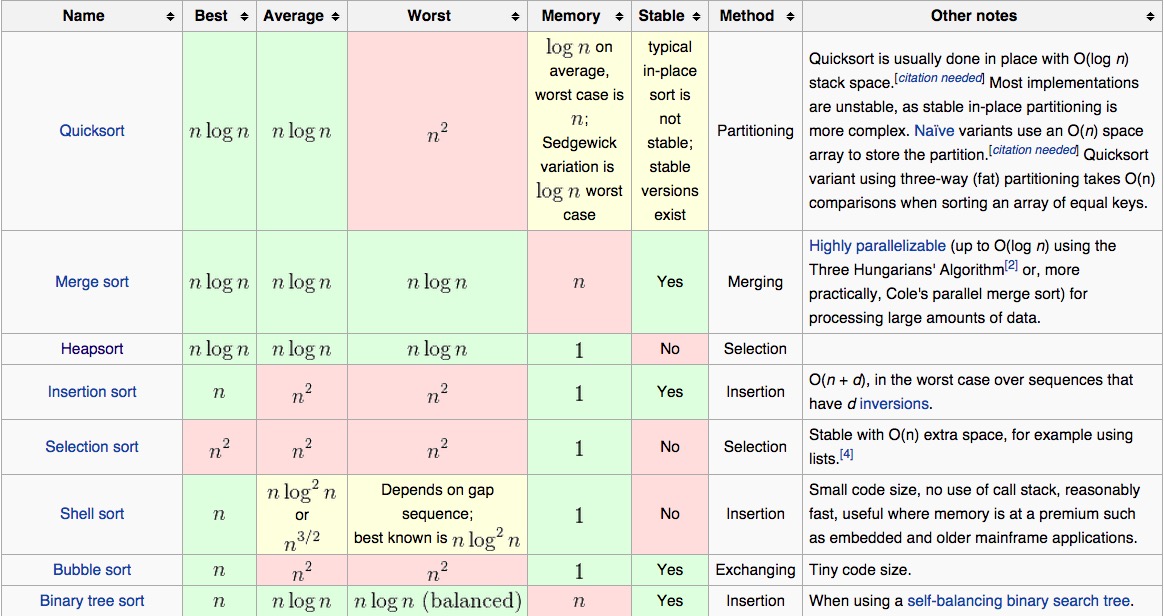
- 性能限制和优势
比较排序有很多性能上的根本限制。在最差情况下,任何一种比较排序至少需要O(nlogn)比较操作.这是比较操作所获的信息有限所导致的,或者说是全序集的模糊代数结构所导致的。从这个意义上讲,归并排序,堆排序在他们必须比较的次数上是渐进最优的。 因此比较排序的最好情况为nlogn的复杂度。
不过,比较排序在控制比较函数方面有显著优势,因此比较排序能对各种数据类型进行排序,并且可以很好地控制一个序列如何被排序。例如,如果倒置比较函数的输出结果可以让排序结果倒置。或者可以构建一个按字典顺序排序的比较函数,这样排序的结果就是按字典顺序的。
比较排序可以更好地适应复杂顺序,例如浮点数。并且,一旦比较函数完成,任何比较算法都可以不经修改地使用;而非比较排序对数据类型的要求更严格。 这种灵活性和上述比较排序在现代计算机的执行效率一起导致了比较排序被更多地应用在了大多数实际工作中。
原始输入数据情况:
- 平均情况:Random
A random initial order is often used to evaluate sorting algorithms in order to elucidate the “typical” case
- 最好情况 Sorting nearly sorted
It is quite common in practice. Some observations:
Insertion sort is the clear winner on this initial condition. Bubble sort is fast, but insertion sort has lower overhead. Shell sort is fast because it is based on insertion sort. Merge sort, heap sort, and quick sort do not adapt to nearly sorted data.
- 最坏情况 Reversed Initial Order
Sorting an array that is initially in reverse sorted order is an interesting case because it is common in practice and it brings out worse-case behavior for insertion sort, bubble sort, and shell sort.
冒泡排序 BubbleSort
- 性能分析
时间复杂度O(n2), 空间复杂度O(1), 稳定,因为存在两两比较,不存在跳跃。 最好是O(n), 最差,平均都是O(n2)
- 步骤
1 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2 对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上。
3 针对所有的元素重复以上的步骤,除了最后一个。
4 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
- 核心代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
45 15 78 84 51 24 12 95 loop:0
15 45 78 51 24 12 84 95 loop:1
15 45 51 24 12 78 84 95 loop:2
15 45 24 12 51 78 84 95 loop:3
15 24 12 45 51 78 84 95 loop:4
15 12 24 45 51 78 84 95 loop:5
12 15 24 45 51 78 84 95 loop:6
- 延伸
冒泡排序缺陷:
在排序过程中,执行完当前的第i趟排序后,可能数据已全部排序完备,但是程序无法判断是否完成排序,会继续执行剩下的(n-1-i)趟排序。解决方法: 设置一个flag位, 如果一趟无元素交换,则 flag = 0; 以后再也不进入第二层循环。
当排序的数据比较多时排序的时间会明显延长,因为会比较 n*(n-1)/2次。
腾讯笔试题:线性表长度为10,在最坏的情况下,冒泡排序需要比较的次数为:40 42 44 45.
答案是45。
Python实现的优化方案: https://github.com/wuchong/Algorithm-Interview/blob/master/Sort/python/BubbleSort.py
- 排序所需的比较次数
当n是所需排序的元素个数时,比较排序所需的比较次数按nlog(n)比例增加。
归并排序 MergeSort
归并排序是采用分治法的一个非常典型的应用。归并排序的思想就是先递归分解数组,再合并数组。1945年由约翰·冯·诺伊曼首次提出。
先考虑合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
再考虑递归分解,基本思路是将数组分解成left和right,如果这两个数组内部数据是有序的,那么就可以用上面合并数组的方法将这两个数组合并排序。如何让这两个数组内部是有序的?可以再二分,直至分解出的小组只含有一个元素时为止,此时认为该小组内部已有序。然后合并排序相邻二个小组即可。
归并排序的时间复杂度,合并耗费O(n)时间,而由完全二叉树的深度可知,整个归并排序需要进行logn次,因此,总的时间复杂度为 O(nlogn),而且这是归并排序算法中最好、最坏、平均的时间性能。
由于归并排序在归并过程中需要与原始记录序列同样数量的存储空间存放归并结果 以及 递归时深度为 logn 的栈空间,因此空间复杂度为O(n+logn)。
另外,对代码进行仔细研究,发现 Merge 函数中有if (arr1[i] < arr2[j]) 语句,这就说明它需要两两比较,不存在跳跃,因此归并排序是一种稳定的排序算法。
也就是说,归并排序是一种比较占用内存,但却效率高且稳定的算法。
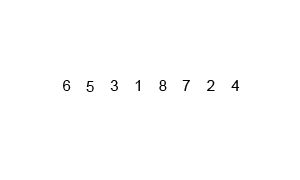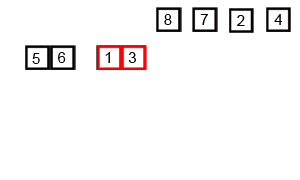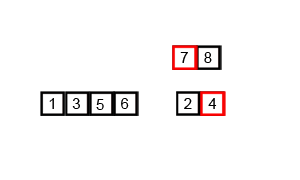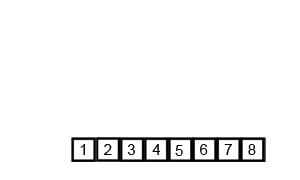
- 核心代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
堆排序 HeapSort
堆排序借助了堆这个数据结构,堆类似二叉树,又具有堆积的性质(子节点的关键值总小于(大于)父节点)。堆排序是采用二叉堆的数据结构来实现的,虽然实质上还是一维数组。二叉堆是一个近似完全二叉树 。
二叉堆具有以下性质:
- 父节点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
- 每个节点的左右子树都是一个二叉堆(都是最大堆或最小堆)。
步骤:
构造最大堆(Build_Max_Heap):若数组下标范围为0~n,考虑到单独一个元素是大根堆,则从下标n/2开始的元素均为大根堆。于是只要从n/2-1开始,向前依次构造大根堆,这样就能保证,构造到某个节点时,它的左右子树都已经是大根堆。 时间复杂度O(n)线性时间建堆。
堆排序(HeapSort):由于堆是用数组模拟的。得到一个大根堆后,数组内部并不是有序的。因此需要将堆化数组有序化。思想是移除根节点,并做最大堆调整的递归运算。第一次将heap[0]与heap[n-1]交换,再对heap[0…n-2]做最大堆调整。第二次将heap[0]与heap[n-2]交换,再对heap[0…n-3]做最大堆调整。重复该操作直至heap[0]和heap[1]交换。由于每次都是将最大的数并入到后面的有序区间,故操作完后整个数组就是有序的了。
最大堆调整(Max_Heapify):该方法是提供给上述两个过程调用的。目的是将堆的末端子节点作调整,使得子节点永远小于父节点 。从而保持堆的性质,时间复杂度O(logn)
对于大数据的处理: 如果对100亿条数据选择Topk数据,选择快速排序好还是堆排序好?
答案是只能用堆排序。 堆排序只需要维护一个k大小的空间,即在内存开辟k大小的空间。而快速排序需要开辟能存储100亿条数据的空间,which is impossible.
- 堆这种数据结构的很好的应用是 优先级队列,如作业调度。 最小堆排序动态过程参考这里http://www.benfrederickson.com/heap-visualization/
快速排序 QuickSort
非比较排序算法
非比较排序算法通过非比较操作能在O(n)完成,这使他们能够回避O(nlogn)这个下界(假设元素是定值)。
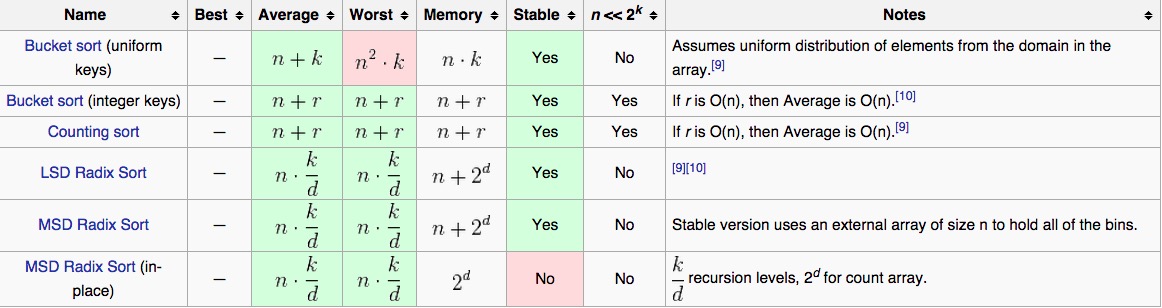
桶排序 BucketSort
计数排序 CountingSort
基数排序 RadixSort
stability
A sorting algorithm is stable if whenever there are two records R and S with the same key, and R appears before S in the original list, then R will always appear before S in the sorted list.
一个典型的例子就是排序扑克牌,在排序前的扑克序列里,梅花4在红桃4前面,排序后顺序不变。如果是non-stable sort,排序后顺序调换。
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,
冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
常用时间复杂度的大小关系:
O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)
参考链接
http://segmentfault.com/a/1190000002595152#articleHeader30
http://wuchong.me/blog/2014/02/09/algorithm-sort-summary/
一个展示排序过程的视频:
http://v.youku.com/v_show/id_XNTkwNzI5OTIw.html
一个展示排序网站:
http://www.sorting-algorithms.com/
当你打开先点击网页上方的Problem Size,选择一个尺寸,20,30,40还是50,于是你就可以看到下面整个大表中有图片显示出来了。如下所示:

其中,
列。是代表每一个排序算法,有“插入”“选择”“冒泡”“Shell”,“合并Merge”,“堆排序”,“快速排序”,“快速3排序”。单击每个一算法的链接,你可以看到这个算法的详细解释,其中包括,算法的伪代码,算法的复杂度,相关的讨论,重点,以及该算法的相关参考文档。
行。是不同的数据样本,第一个是“随机样本”,第二个是“几乎排好序的样本”,第三个是“最差的样本(反序)”,第四个是“有一些相同项的样本”。这些样本在不同的算法上都会有不同的表现。
单元格。每个单元格都是一个图片。简单的用鼠标单击一下每个图片,可以动画地演示算法整个过程。其中两个小红箭头表示了正在需要“交换顺序的数据”。